17 Evaluation of Models
Once we obtain the model with the training data, we need to evaluate it on unseen test data.
No Free Lunch theorem In the absence of any knowledge about the prediction problem, no model can be said to be uniformly better than any other
17.1 Learning Objectives and Evaluation Lens
- Objective: estimate how well a model generalizes to unseen software engineering data.
- Validation: holdout, repeated holdout, and cross-validation depending on dataset size.
- Primary principle: no information from test data may influence training or preprocessing.
- Common pitfalls: leakage, overfitting during tuning, and reporting only one metric.
17.2 What Is Often Missing in Model Evaluation
In many studies, these critical points are under-reported:
- Baseline comparison (for example, random/naive/majority baselines)
- Uncertainty estimates (confidence intervals or repeated-run variability)
- Threshold policy for turning probabilities into labels
- Temporal validation when data is time-ordered
- Error analysis by subgroup/release/module type
Including these points improves rigor and reproducibility.
17.3 Building and Validating a Model
We cannot use the same data for training and test. Doing so is like evaluating a student with exercises already solved in class: results will be optimistic and we will not measure generalization capability.
Therefore, we should, at a minimum, divide the dataset into training and testing, learn the model with the training data and test it with the rest of data as explained next.
17.3.1 Holdout approach
Holdout approach consists of dividing the dataset into training (typically approx. 2/3 of the data) and testing (approx 1/3 of the data). + Problems: Data can be skewed, missing classes, etc. if randomly divided. Stratification ensures that each class is represented with approximately equal proportions (e.g., if data contains approximately 45% of positive cases, train and test splits should keep similar proportions of positive cases).
Holdout estimate can be made more reliable by repeating the process with different subsamples (repeated holdout method).
The error rates on the different iterations are averaged (overall error rate).
- Usually, part of the data points are used for building the model and the remaining points are used for validating the model. There are several approaches to this process.
- Validation Set approach: it is the simplest method. It consists of randomly dividing the available set of observations into two parts, a training set and a validation set or holdout set. set. Usually 2/3 of the data points are used for training and 1/3 is used for testing purposes.

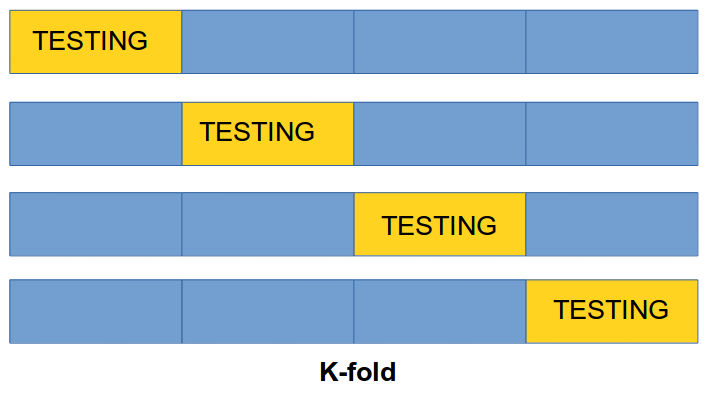
17.3.2 Cross Validation (CV)
k-fold Cross-Validation involves randomly dividing the set of observations into \(k\) groups, or folds, of approximately equal size. One fold is treated as a validation set and the method is trained on the remaining \(k-1\) folds. This procedure is repeated \(k\) times. If \(k\) is equal to \(n\) we are in the previous method.
1st step: split dataset (\(\cal D\)) into \(k\) subsets of approximately equal size \(C_1, \dots, C_k\)
2nd step: we construct a dataset \(D_i = D-C_i\) used for training and test the accuracy of the classifier \(D_i\) on \(C_i\) subset for testing
Having done this for all \(k\) we estimate the accuracy of the method by averaging the accuracy over the \(k\) cross-validation trials
17.3.3 Leave-One-Out Cross-Validation (LOO-CV)
- Leave-One-Out Cross-Validation (LOO-CV): This is a special case of CV. Instead of creating two subsets for train and test, a single observation is used for the validation set, and the remaining observations make up the training set. This approach is repeated \(n\) times (the total number of observations) and the estimate for the test mean squared error is the average of the \(n\) test estimates.
